39 in supervised learning class labels of the training samples are known
Supervised Multi-labeling classifier - IBM The word supervised means that this classifier uses supervised learning, a type of machine learning method that requires training data to learn how to recognize classes of documents based on their metadata and keywords in text. On the other hand, the word multi-labeling means it may give zero or more labels to a single document. LaSSL: Label-Guided Self-Training for Semi-supervised Learning The key to semi-supervised learning (SSL) is to explore adequate information to leverage the unlabeled data. Current dominant approaches aim to generate pseudo-labels on weakly augmented instances and train models on their corresponding strongly augmented variants with high-confidence results.
scikit-learn.org › stable › modules3.3. Metrics and scoring: quantifying the quality of ... The label_ranking_loss function computes the ranking loss which averages over the samples the number of label pairs that are incorrectly ordered, i.e. true labels have a lower score than false labels, weighted by the inverse of the number of ordered pairs of false and true labels. The lowest achievable ranking loss is zero.
In supervised learning class labels of the training samples are known
PDF Supervised Learning: Classificaon - fenyolab.org • The known label of test sample is compared with the classified result from the model • Accuracy rate is the percentage of test set samples that are correctly classified by the model • Test set is independent of training set (otherwise over-fing) • If the accuracy is acceptable, use the model to classify new data What is Supervised Learning? - tutorialspoint.com Supervised learning, one of the most used methods in ML, takes both training data (also called data samples) and its associated output (also called labels or responses) during the training process. The major goal of supervised learning methods is to learn the association between input training data and their labels. supervised learning and labels - Data Science Stack Exchange 5. The main difference between supervised and unsupervised learning is the following: In supervised learning you have a set of labelled data, meaning that you have the values of the inputs and the outputs. What you try to achieve with machine learning is to find the true relationship between them, what we usually call the model in math.
In supervised learning class labels of the training samples are known. City of Calgary (@cityofcalgary) / Twitter Aug 21, 2008 · October is a busy month for pedestrians. Kids are back in school, people are out enjoying the last bit of nice weather & of course, Halloween 🎃 Whether driving, riding or walking, we all have a responsibility to keep each other safe Click ⬇️ for monthly road safety tips. PDF Semi-Supervised Learning with Very Few Labeled Training Examples As other semi-supervised learning methods, co-training style methods require a number of labeled training exam-ples to be available. In particular, such methods cannot work well when there is only one labeled training exam-ple. There are many one-class methods that can be applied when there are only positive examples, but they require a Types Of Machine Learning: Supervised Vs Unsupervised Learning Supervised learning is learning with the help of labeled data. The ML algorithms are fed with a training dataset in which for every input data the output is known, to predict future outcomes. This model is highly accurate and fast, but it requires high expertise and time to build. Also, these models require rebuilding if the data changes. (PDF) Supervised Learning - ResearchGate As the output is regarded as the label of the input data or the supervision, an input-output training sample is also called labelled training data, or supervised data. Occasionally, it is also...
› book › ch066. Learning to Classify Text - NLTK 1 Supervised Classification. Classification is the task of choosing the correct class label for a given input. In basic classification tasks, each input is considered in isolation from all other inputs, and the set of labels is defined in advance. Some examples of classification tasks are: Deciding whether an email is spam or not. learn.microsoft.com › en-us › dotnetMachine learning tasks - ML.NET | Microsoft Learn Mar 18, 2022 · A supervised machine learning task that is used to predict the class (category) of an image but also gives a bounding box to where that category is within the image. Instead of classifying a single object in an image, object detection can detect multiple objects within an image. Semi-Supervised Learning, Explained | AltexSoft Semi-supervised learning bridges supervised learning and unsupervised learning techniques to solve their key challenges. With it, you train an initial model on a few labeled samples and then iteratively apply it to the greater number of unlabeled data. Unlike unsupervised learning, SSL works for a variety of problems from classification and ... developers.google.com › machine-learning › glossaryMachine Learning Glossary | Google Developers Jul 18, 2022 · A type of supervised learning whose objective is to order a list of items. rank (ordinality) The ordinal position of a class in a machine learning problem that categorizes classes from highest to lowest. For example, a behavior ranking system could rank a dog's rewards from highest (a steak) to lowest (wilted kale). rank (Tensor)
Decision tree learning - Wikipedia Decision Tree Learning is a supervised learning approach used in statistics, data mining and machine learning.In this formalism, a classification or regression decision tree is used as a predictive model to draw conclusions about a set of observations.. Tree models where the target variable can take a discrete set of values are called classification trees; in these tree … 2.7. Novelty and Outlier Detection - scikit-learn The scores of abnormality of the training samples are accessible through the negative_outlier_factor_ attribute. If you really want to use neighbors.LocalOutlierFactor for novelty detection, i.e. predict labels or compute the score of ... The nu parameter, also known as the margin of the One-Class SVM, corresponds to the probability of finding ... en.wikipedia.org › wiki › Supervised_learningSupervised learning - Wikipedia Supervised learning (SL) is the machine learning task of learning a function that maps an input to an output based on example input-output pairs. It infers a function from labeled training data consisting of a set of training examples . [2] In supervised learning, class labels of the training samples are ... Supervised learning refers to a machine learning concept whereby the data has a labels upon which the training data learns. Hence, the class labels are known.. Class labels refers to the predictions which we expect the machine learning algorithm to learn from and then make accurate predictions on the test data.; Supervised and unsupervised learning differs in that class labels are known in ...
Using Unlabeled Data for Supervised Learning
Supervised Learning: Basics of Classification and Main Algorithms Based on the features of the training set, the decision tree learns a series of questions to infer the class labels of the samples. The starting node is called the tree root, and the algorithm will split the dataset on the feature that contains the maximum Information Gain iteratively, until the leaves (the final nodes) are pure.

Unstructured Data Classification.txt - In Supervised learning ...
› indexPHSchool.com Retirement–Prentice Hall–Savvas Learning Company About a purchase you have made. FAQs: order status, placement and cancellation & returns; Contact Customer Service
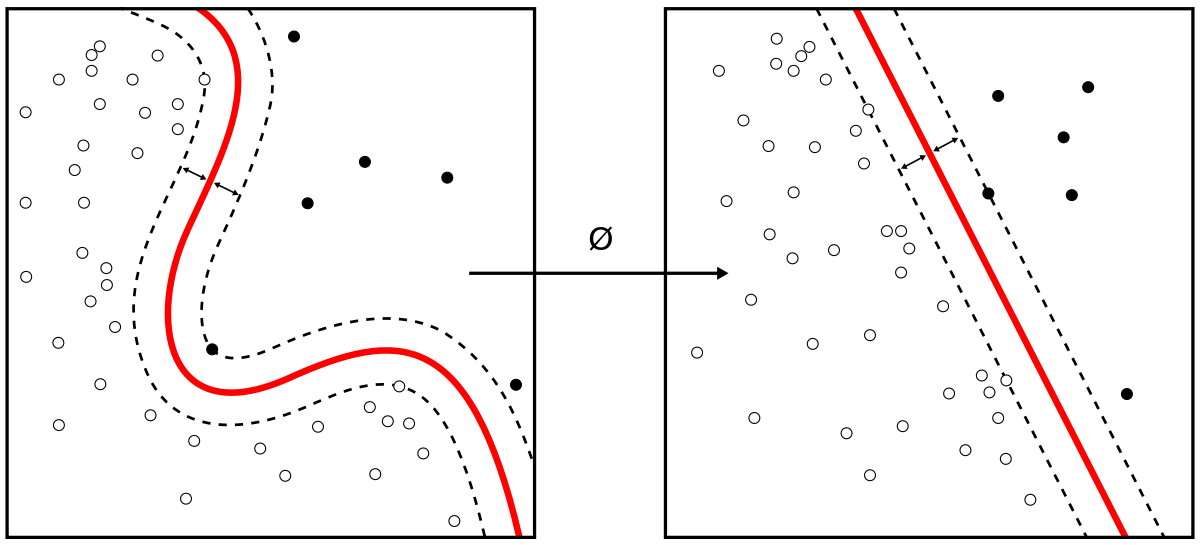
Supervised learning - Wikipedia
Supervised Learning in Absence of Accurate Class Labels Measuring complexity of systems is very important in Cybernetics. An aging human heart has a lower complexity than that of a younger one indicating a higher risk of cardiovascular diseases, pseudo-random sequences used in secure information storage

Supervised Machine Learning - an overview | ScienceDirect Topics
Unstructured Data Classification.txt - In Supervised learning, class ... in supervised learning, class labels of the training samples are known select pre-processing techniques from the options all the options a classifer that can compute using numeric as well as categorical values is random forest classifier classification where each data is mapped to more than one class is called multi-class classification tf-idf is …

Supervised Learning - an overview | ScienceDirect Topics
Supervised learning | Engati A supervised learning algorithm analyzes the training data and produces an inferred function, which can be used for mapping new examples. An optimal scenario will allow for the algorithm to correctly determine the class labels for unseen instances.

In supervised learning, class labels of the training samples ...
[Solved]: Question 84 In Supervised learning, class labels # In supervised learning, class labels of the training samples are "known." • The correct answer is "known." # Supervised learning uses a training set to teach models to yield the desir
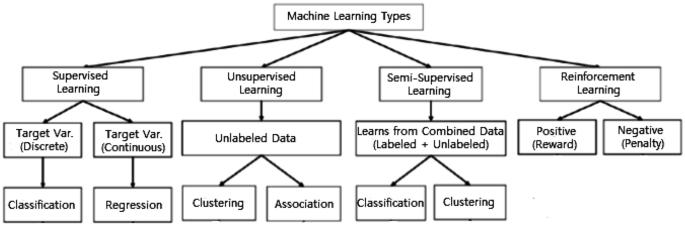
Machine Learning: Algorithms, Real-World Applications and ...
PDF Supervised Learning in Absence of Accurate Class Labels: a Multi ... samples and corresponding labels associated with that data. The goal of building a classifier is then to find a suitable boundary that can predict correct labels on test or unseen data. A lot of research has been carried out to build robust supervised learning algorithms that can battle the challenges of nonlinear separations, class imbalances etc
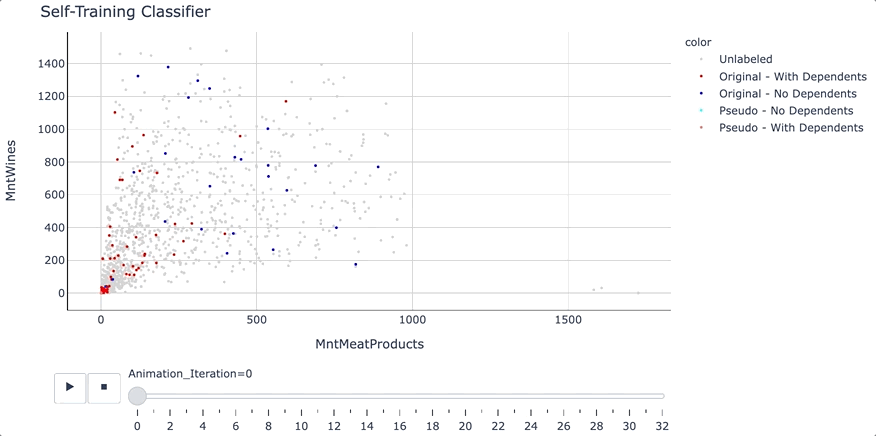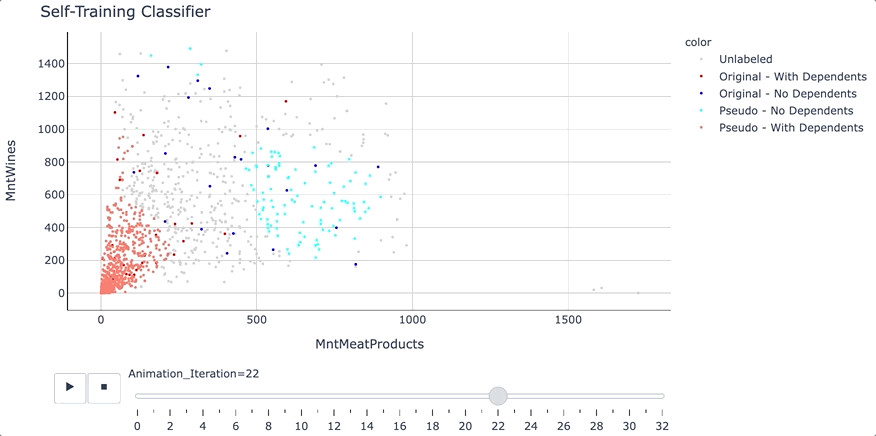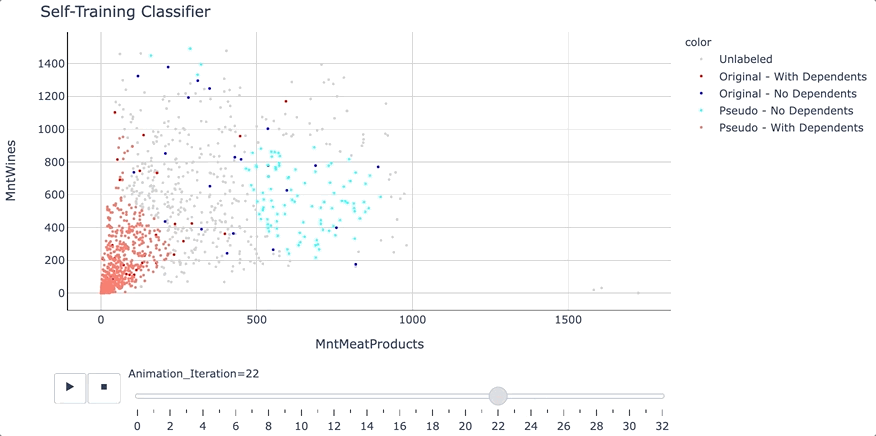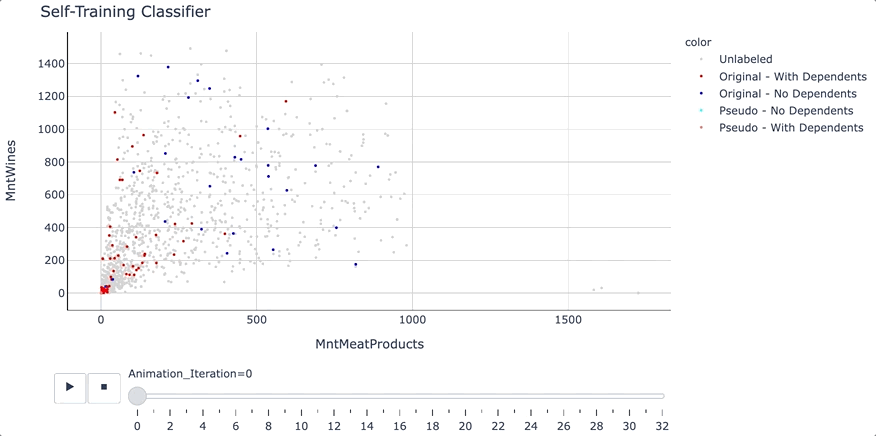
Self-Training Classifier: How to Make Any Algorithm Behave ...
Supervised Learning - an overview | ScienceDirect Topics The procedure of Supervised Learning can be described as the follows: we use x(i) to denote the input variables, and y(i) to denote the output variable. A pair ( x(i), y(i)) is a training example, and the training set that we will use to learn is { ( x(i), y(i) ), i = 1, 2, …, m }. ( i) in the notation is an index into the training set.
Supervised vs Unsupervised Learning: Difference Between Them
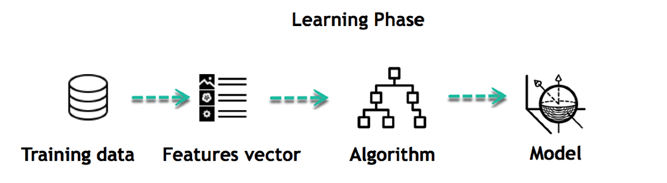
Basics of Supervised Learning (Classification) | by Tarun Gupta ... They are namely Learning and Querying phase. The learning phase consists of two components of namely Induction (training) and Deduction (testing). The querying phase is also known as application phase. Let's talk about it in a more formal way now. Formal definition: Improve over task T, with respect to performance measure P, based on experience E.
![Supervised vs. Unsupervised Learning [Differences & Examples]](https://assets-global.website-files.com/5d7b77b063a9066d83e1209c/627d12509bceec03c52a4feb_616b63f3b531b95ff6a35dea_data-in-supervised-vs-unsupervised-cover.png)
Supervised vs. Unsupervised Learning [Differences & Examples]
Best Practices for Improving Your Machine Learning and Deep Learning … Jul 22, 2022 · The lack of gold standard annotated training data is a common bottleneck for developing and improving large-scale supervised machine learning and deep learning models. The cost of annotation in terms of time, expense, and subject matter expertise is a limiting factor to create massive labeled training datasets.
An overview of proxy-label approaches for semi-supervised ...
Hands-on Machine Learning with Scikit-Learn, Keras and … Dec 24, 2019 · Semi-supervised Learning: If you only have a few labels, you could perform clustering and propagate the labels to all the instances in the same cluster. This technique can greatly increase the number of labels available for a subsequent supervised learning algorithm, and thus improve its performance; Search Engines

What is Supervised Learning? | TIBCO Software
Supervised Classification | Google Earth Engine | Google Developers Dec 20, 2021 · In this example, the training points in the table store only the class label. Note that the training property ('landcover') stores consecutive integers starting at 0 (Use remap() on your table to turn your class labels into consecutive integers starting at zero if necessary).Also note the use of image.sampleRegions() to get the predictors into the table and create a …

Machine Learning
en.wikipedia.org › wiki › Decision_tree_learningDecision tree learning - Wikipedia Decision Tree Learning is a supervised learning approach used in statistics, data mining and machine learning.In this formalism, a classification or regression decision tree is used as a predictive model to draw conclusions about a set of observations.
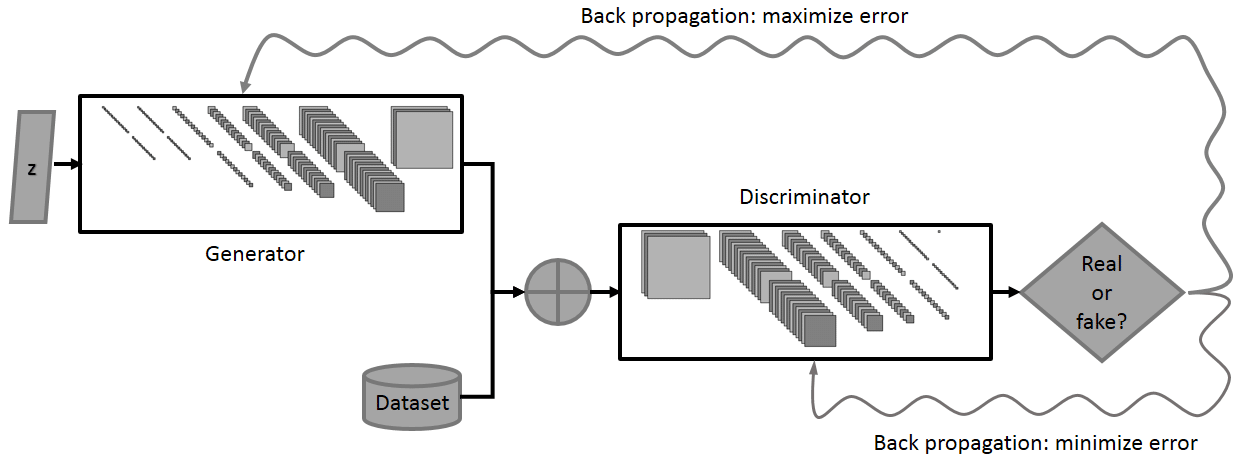
Difference Between Supervised, Unsupervised, & Reinforcement ...
supervised learning and labels - Data Science Stack Exchange 5. The main difference between supervised and unsupervised learning is the following: In supervised learning you have a set of labelled data, meaning that you have the values of the inputs and the outputs. What you try to achieve with machine learning is to find the true relationship between them, what we usually call the model in math.

What Is Training Data? How It's Used in Machine Learning
What is Supervised Learning? - tutorialspoint.com Supervised learning, one of the most used methods in ML, takes both training data (also called data samples) and its associated output (also called labels or responses) during the training process. The major goal of supervised learning methods is to learn the association between input training data and their labels.

Semi-supervised Image Classification With Unlabeled Data | Toptal
PDF Supervised Learning: Classificaon - fenyolab.org • The known label of test sample is compared with the classified result from the model • Accuracy rate is the percentage of test set samples that are correctly classified by the model • Test set is independent of training set (otherwise over-fing) • If the accuracy is acceptable, use the model to classify new data
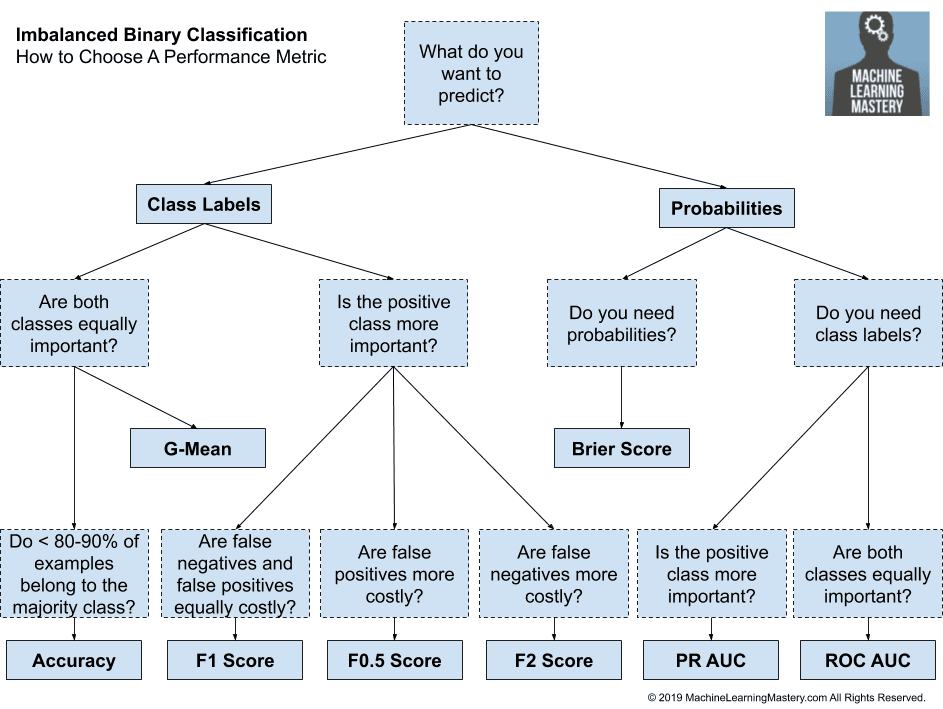
Tour of Evaluation Metrics for Imbalanced Classification

Pro Tips: How to deal with Class Imbalance and Missing Labels ...

Supervised learning - Wikipedia

Solved Section VI: Miscellaneous - Each question carries 2 ...

Supervised Learning With Python: What to Know | Built In

Categories of Machine Learning systems :: InBlog
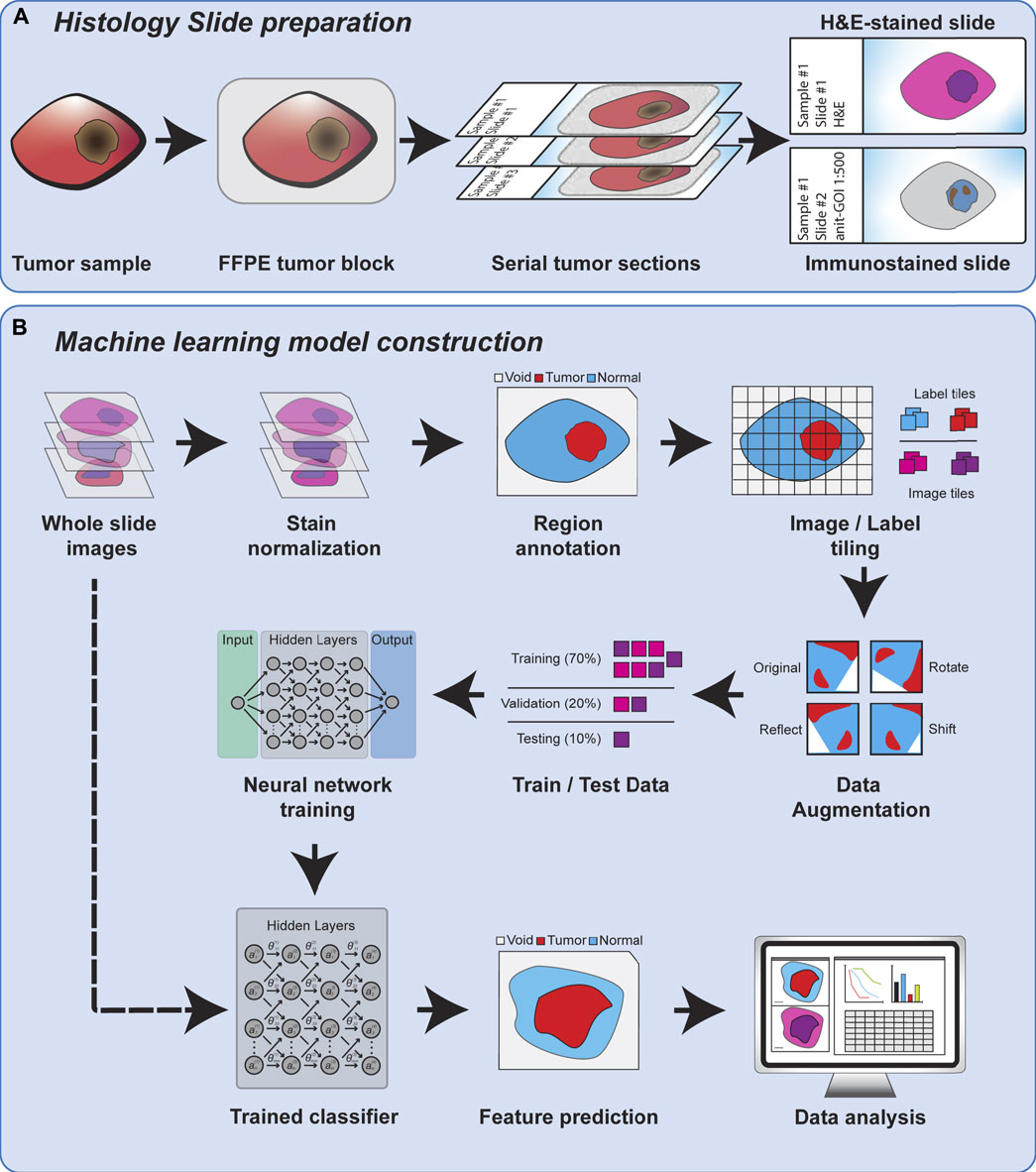
Frontiers | Deep Learning of Histopathology Images at the ...

Solved Section VI: Miscellaneous - Each question carries 2 ...
Deep learning with noisy labels: exploring techniques and ...

Supervised, unsupervised and semi-supervised learning. (a) In ...
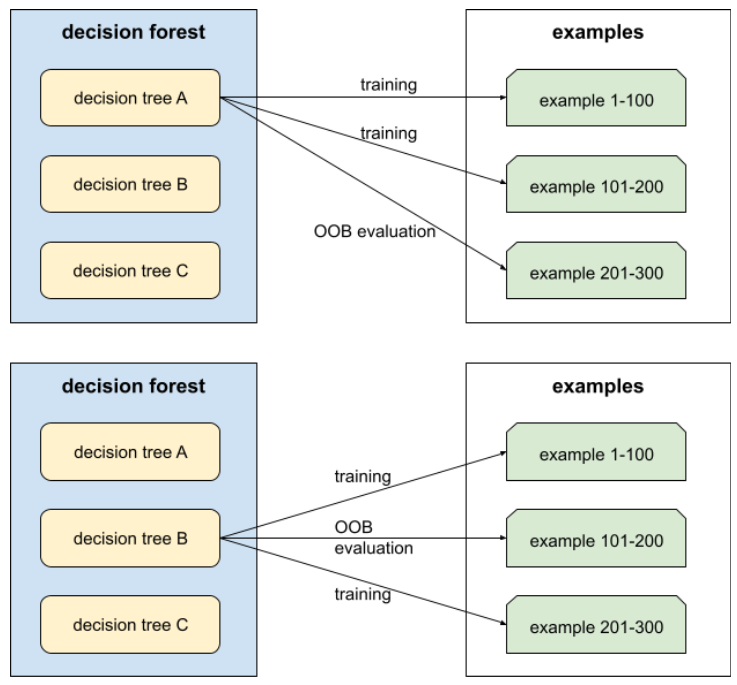
Machine Learning Glossary | Google Developers

FixMatch: A Semi-Supervised Learning method, that can be ...
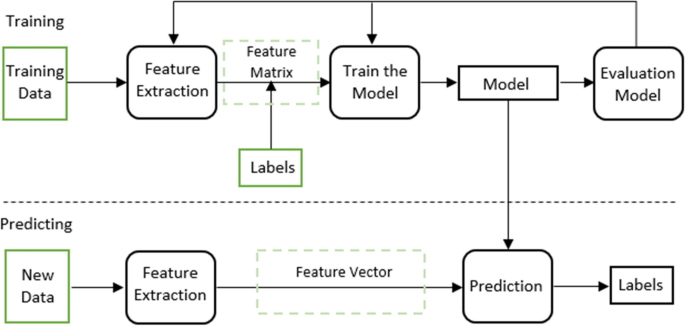
Evaluating student levelling based on machine learning ...
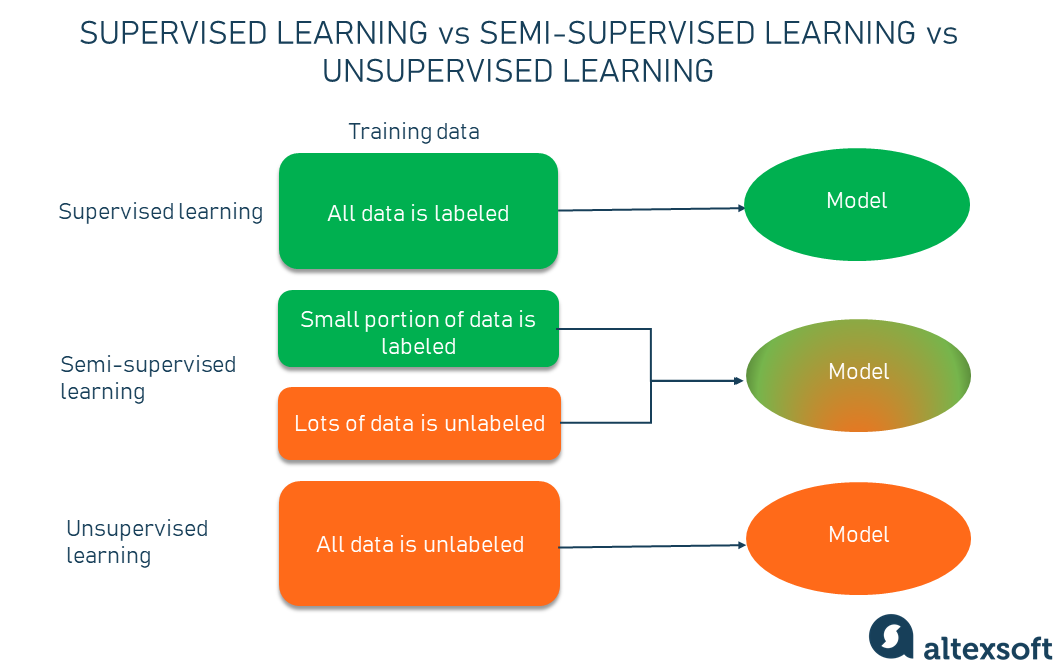
Semi-Supervised Learning, Explained | AltexSoft

43 in supervised learning class labels of the training ...

Supervised Learning - an overview | ScienceDirect Topics
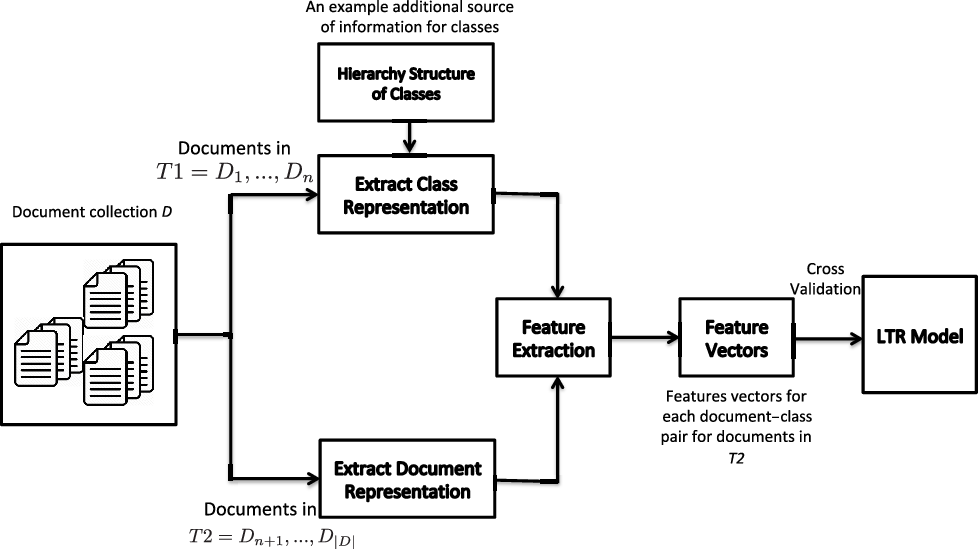
Learning to rank for multi-label text classification ...
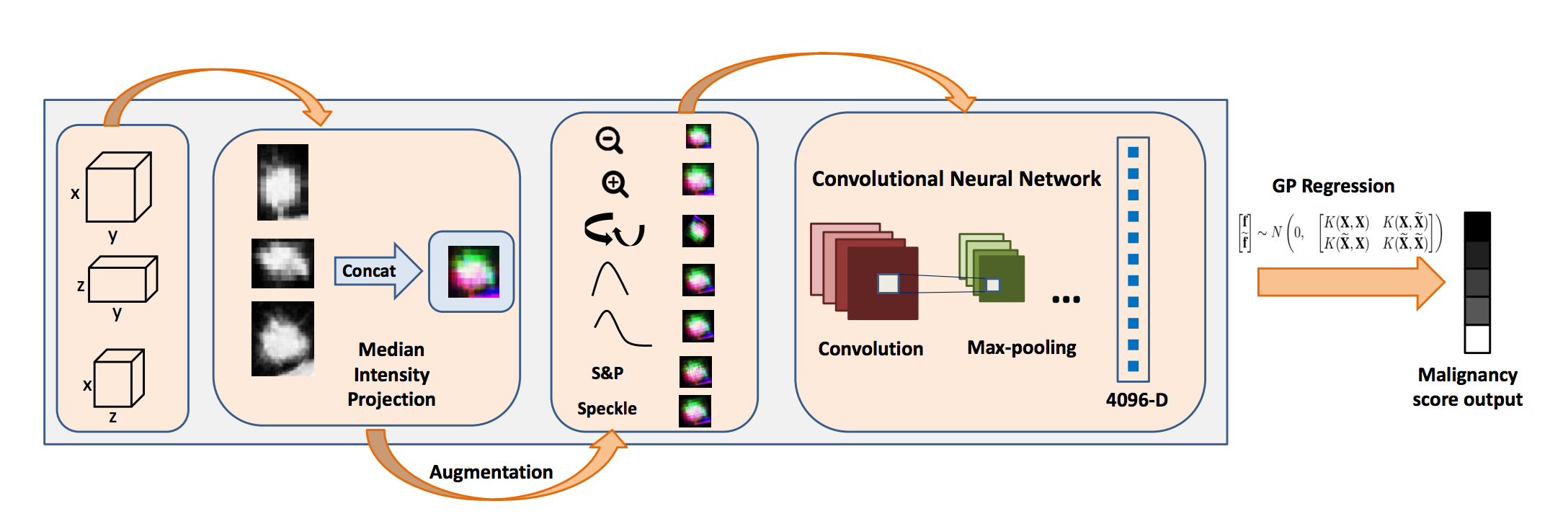
Pro Tips: How to deal with Class Imbalance and Missing Labels ...

Text Classifiers in Machine Learning: A Practical Guide

A Cluster-then-label Semi-supervised Learning Approach for ...
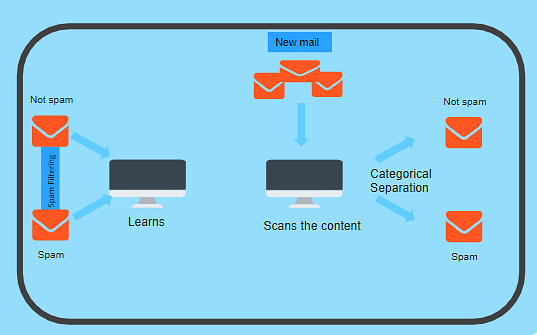
Supervised and Unsupervised Learning in (Machine Learning)
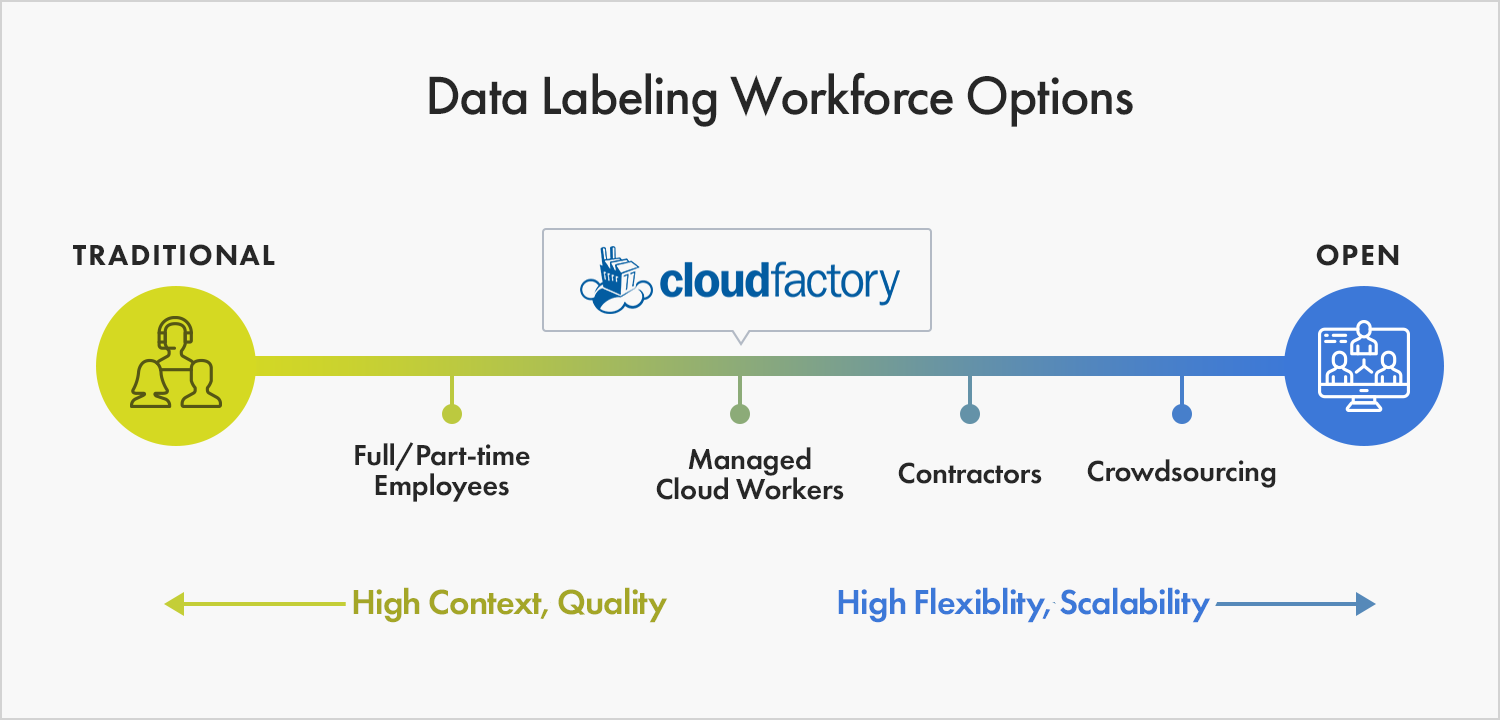
The Ultimate Guide to Data Labeling for Machine Learning

Machine Learning
Post a Comment for "39 in supervised learning class labels of the training samples are known"